Cleanlab is an AI platform and popular Python library that automatically detects and corrects errors in machine learning datasets and AI application outputs. Born from MIT research, it helps data scientists, engineers, and businesses improve AI reliability by identifying mislabeled data, outliers, and hallucinated or unsafe responses in Generative AI and RAG applications.
Cleanlab (cleanlab.ai) is an enterprise AI and data-centric machine learning platform that specializes in finding and fixing errors in real-world data and ensuring the safety of AI applications. Spun out of MIT research, it offers both an open-source Python library and a commercial no-code platform (Cleanlab Studio).
Core Product Offerings:
1. AI Safety & Agentic Guardrails -
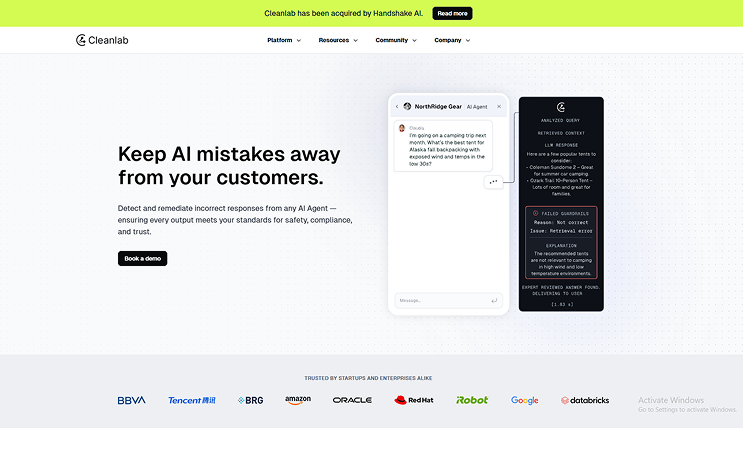
Cleanlab provides an independent evaluation and trust layer that wraps around any Large Language Model (LLM) or Retrieval-Augmented Generation (RAG) system.
- Real-Time Monitoring: Logs and scores every AI input and output to check for fabrication, hallucinations, or unsafe behavior.
- Guardrails: Automatically applies interventions (like blocking
bad responses or triggering fallbacks) to prevent unreliable AI outputs from reaching users.
2. Cleanlab Studio (No-Code & Automation)
A browser-based platform designed to clean datasets without writing code.
- Automated Data Cleaning: Automatically identifies mislabeled data points, outliers, near-duplicates, and dataset-level drifts.
- Smart Data Editing: Provides an intuitive interface to review individual data points, correct annotations in bulk, and auto-label previously unlabeled data.
- Deployment Options: Available as a Cloud (SaaS) solution or can be deployed privately within an organization's Virtual Private Cloud (VPC).
3. Open-Source Python Library
The foundational framework that powers data-centric AI by integrating with existing ML models (PyTorch, TensorFlow, HuggingFace, XGBoost, etc.).
- Datalab: A built-in diagnostic tool that analyzes model outputs and embeddings to flag various data quality issues.
- CleanLearning: Adapts any standard classification model to be robust and performant, even when trained on noisy or partially mislabeled datasets.
- CrowdLab: Evaluates data labeled by multiple annotators (crowdsourcing) to establish consensus labels and measure the quality of the annotators themselves.
- ActiveLab: Recommends which data points should be (re)labeled next to maximize the accuracy and efficiency of model training.
What Problems Does it Solve?
- What Problems Does it Solve?
- AI Hallucinations: Prevents enterprise AI agents from confidently providing incorrect or hallucinated answers based on flawed knowledge bases.
- Manual Data Prep: Offloads the tedious 80% of data science work spent on data curation and cleaning to automated, mathematically grounded algorithms.
Target Audience & Compatibility
- Users: Machine learning engineers, data scientists, customer support teams, and subject matter experts (SMEs).
- Supported Data Types: Compatible with any modality, including images, text, tabular data, and audio.
If you want, I can help you decide how to use Cleanlab by sharing:
- The differences between the Open Source and Studio (Enterprise) versions.
- Setup steps to integrate the Datalab module into your current Python environment.
- How Cleanlab tackles Retrieval-Augmented Generation (RAG) hallucinations.